Isolation and multi-versioning in database systems
Database systems can use two techniques to process record updates; update-in-place and multi-versioning (also known as multi-version concurrency control or MVCC). Update-in-place destructively updates records by overwriting their values. MVCC maintains multiple copies, or versions, of each record. Each update to a particular record creates a new version, while the record’s preceding value is preserved in an old version. In theory, therefore, MVCC can allow conflicting writes and reads to proceed in parallel; writes create new versions, while reads can be directed to older versions. In contrast, update-in-place systems need some form of mutual exclusion between conflicting writes and reads. Do these properties imply that MVCC obviates isolation mechanisms, such as locking, used in update-in-place systems? The short answer is no.
The problem is that MVCC, as described above, provides a form of mutual exclusion among readers and writers on a single database object, while isolation is a more abstract guarantee that specifies the order in which transactions can read or write multiple objects. For this reason, database locking protocols, such as two-phase locking, are far more complex than locking disciplines used in concurrent programs. In general, this implies that using MVCC cannot eliminate the use of locking mechanisms in your database system. Furthermore, if your database implements MVCC “without locking” then in all likelihood, it is not running transactions under serializable isolation. Applications should be aware of this caveat, and carefully understand the implications of running transactions under a level of isolation weaker than serializability. Examples of database systems that implement some form of MVCC “without locking” are: Oracle 11c, SAP HANA, NuoDB, and Postgres. Interestingly, both Oracle 11c and SAP HANA erroneously claim that their MVCC protocols are serializable, when in reality they implement snapshot isolation, the subject of the rest of this post.
MVCC “without locking” is usually taken to mean an isolation level called snapshot isolation. In snapshot isolation, each transaction executes against a consistent snapshot of the database. A snapshot is effectively a private workspace; an executing transaction does not observe the updates of other concurrent transactions in its workspace. A transaction’s updates are buffered in its private workspace, and written out as new versions when the transaction finishes executing. Snapshot isolation disallows concurrent conflicting writes (write-write conflicts), but permits conflicting reads and writes; a transaction’s reads are directed to versions in its private workspace, while writes create new versions that do not perturb other transactions’ workspaces. Snapshot isolation is a very useful level of isolation; among other things, it guarantees that the database state observed by a transaction does not change during the course of its execution. As a consequence, snapshot isolation provides stronger guarantees than isolation levels such as read committed. Nonetheless, snapshot isolation is not serializable, and is therefore susceptible to concurrency anomalies that serializable isolation is not.
Consider a banking application in which customers have checking and savings accounts. The application requires that the sum of the balances in each customer’s savings and checking accounts is never negative. Every transactions that needs to withdraw money from either the savings or checking accounts first checks that this constraint holds. Consider a scenario where a particular customer’s savings and checking accounts contain $100 and $50, respectively. Transaction T0 tries to withdraw $100 from the savings account, while transaction T1 tries to withdraw $75 from the checking account. The total amount both transactions attempt to withdraw is $175, while the customer’s accounts contain only $150 in total. Both transactions first check that enough balance exists prior to performing a withdrawal. Therefore, if one transaction successfully performs a withdrawal, the other must not. A serializable execution of T0 and T1 would ensure that at most one transaction successfully performs a withdrawal, guaranteeing that the constraint on a customer’s checking and savings account balances holds.
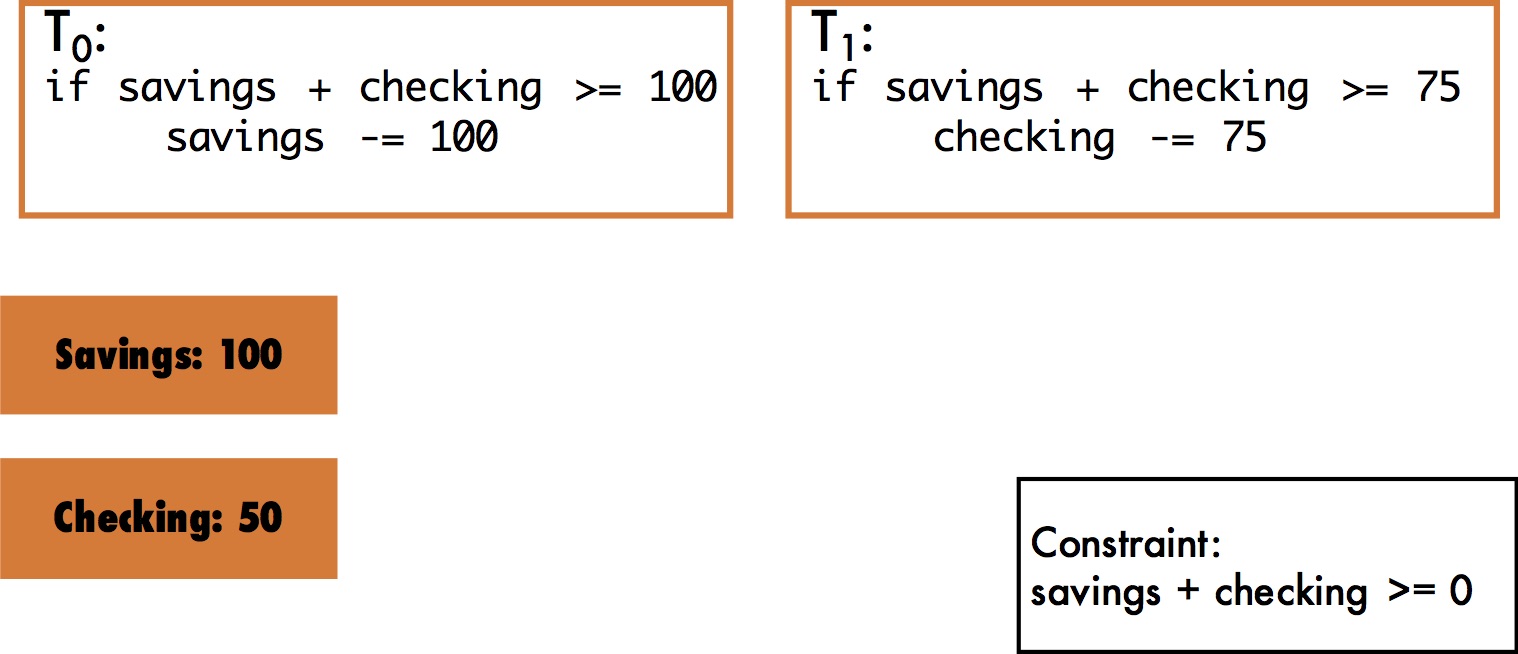
Snapshot isolation does not ensure that the application constraint holds. Under snapshot isolation, both transactions may execute in workspaces in which the customer’s savings and checking balances are $100 and $50, while being unaware of each others’ writes. Furthermore, T0 and T1 do not perform conflicting writes, snapshot isolation therefore determines that they do not conflict. As a consequence, both transactions may end up performing their withdrawals, leaving the customer’s savings and checking accounts with $0 and -$25 respectively. This is an example of the well known write-skew anomaly.

The banking example illustrates that snapshot isolation (or MVCC “without locking”) is susceptible to concurrency anomalies that serializability is not. It should be noted that snapshot isolation is generally considered a “strong” isolation level; certain applications can execute correctly without resorting to the use of serializable isolation. Importantly, however, correctness under snapshot isolation is application dependent. Applications should not assume that MVCC is a silver bullet that obviates the need for locking, while still guaranteeing serializable isolation. Instead, they should evaluate whether their correctness subtly depends on the differences between serializable and snapshot isolation, and whether they can tolerate anomalies introduced by snapshot isolation.
Useful links
Two of my favorite academic papers discussing the subtle differences between various isolation levels:
Papers on snapshot isolation anomalies (courtesy of Alan Fekete and his collaborators):
Jose Faleiro is a computer science PhD candidate at Yale University. His research is focussed on building performant and robust large-scale concurrent systems. More information on his research can be found on his home-page.